
From 2022 to January 2025, I pursued my Master’s degree at the School of Electrical and Information Engineering, Tianjin University, under the supervision of Associate Prof. Jiale Cao.
Since January 2025, I have been working as a Researcher in the Foundation Model Group at MEGVII Technology.
My research interests primarily focus on three areas: (1) Robotics, (2) Multi-Modal, and (3) RL.
We are hiring research interns all year round, please feel free to drop me your resume at bin_xie@tju.edu.cn.
🔥 News
- 2025.11: One paper (SpatialActor) is accepted by AAAI 2026 (Oral). Congratulations to @Hao Shi !
- 2025.10: One paper (SED++) is accepted by IEEE TPAMI 2025.
- 2025.01: One paper (Glad) is accepted by ICLR 2025.
- 2024.11: I’m awarded National Scholarship!
Publications
Preprint Papers
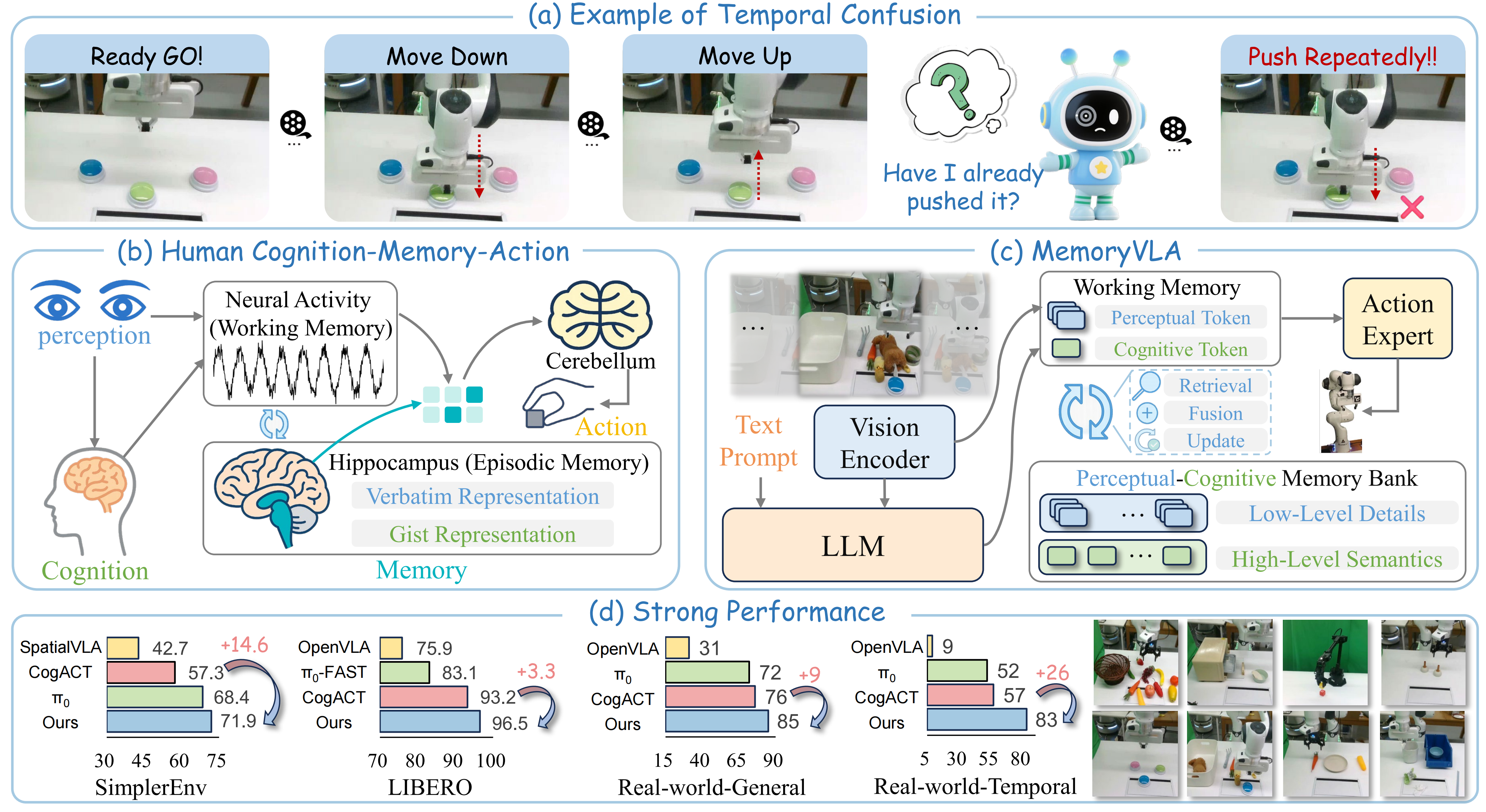
MemoryVLA: Perceptual-Cognitive Memory in Vision-Language-Action Models for Robotic Manipulation
Paper | Demo
Hao Shi, Bin Xie, Yingfei Liu, Lin Sun, Fengrong Liu, Tiancai Wang, Erjin Zhou, Haoqiang Fan, Xiangyu Zhang, Gao Huang
- MemoryVLA is a Cognition-Memory-Action framework for long-horizon robotic manipulation inspired by human working memory and hippocampal systems. It uses a Perceptual-Cognitive Memory Bank to store temporal context and adaptively fuses past experience with current observations for temporally aware action generation.
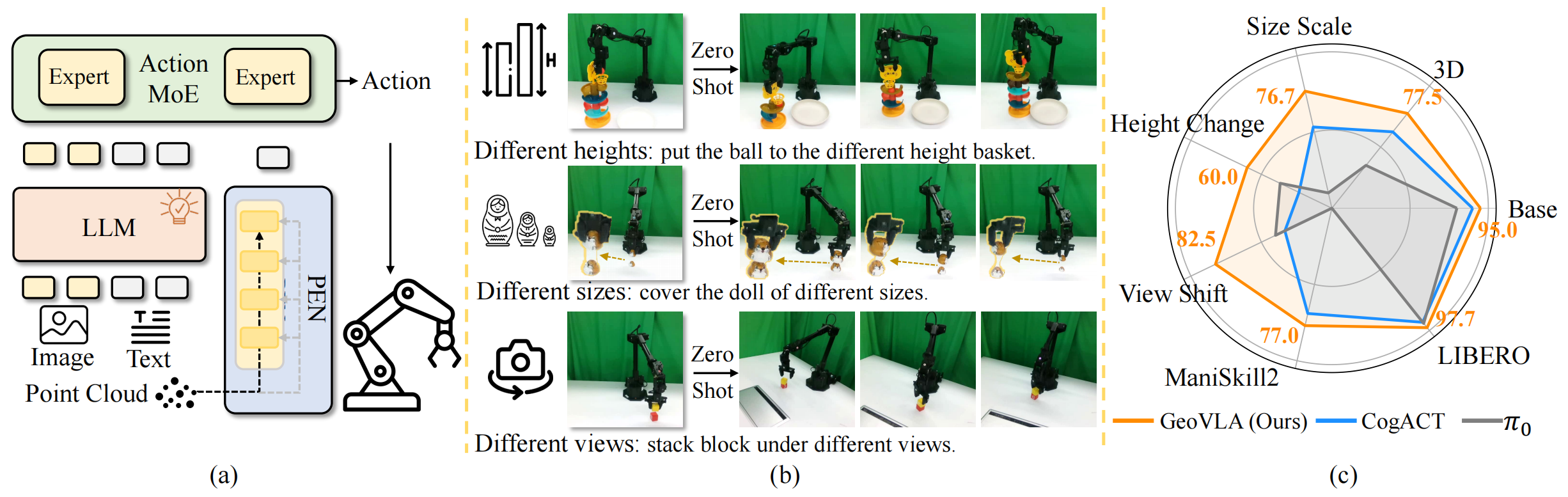
GeoVLA: Empowering 3D Representations in Vision-Language-Action Models
Paper | Demo
Lin Sun, Bin Xie, Yingfei Liu, Hao Shi, Tiancai Wang, Jiale Cao
- GeoVLA is a vision-language-action framework that integrates 3D geometry for better robotic manipulation. It fuses image-language data with point cloud features to enhance spatial awareness, achieving state-of-the-art performance and robustness in simulation and real-world tasks.
Published Papers

SpatialActor: Exploring Disentangled Spatial Representations for Robust Robotic Manipulation
Hao Shi, Bin Xie, Yingfei Liu, Yang Yue, Tiancai Wang, Haoqiang Fan, Xiangyu Zhang, Gao Huang
- SpatialActor is a disentangled framework for robust robotic manipulation. It decouples perception into complementary high-level geometry from fine-grained but noisy raw depth and coarse but robust depth expert priors, along with low-level spatial cues and appearance semantics.
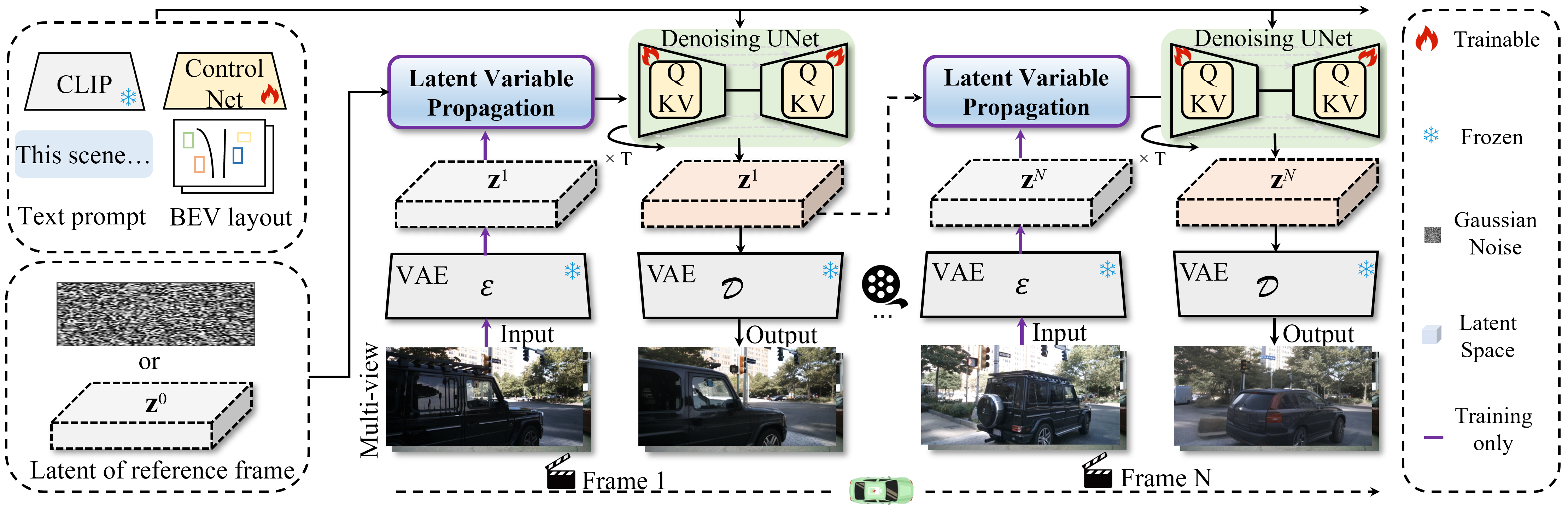
Glad: A Streaming Scene Generator for Autonomous Driving
Paper
Bin Xie, Yingfei Liu, Tiancai Wang, Jiale Cao, Xiangyu Zhang
- Glad is an efficient framework for generating video data in autonomous driving scenarios. It produces temporally coherent videos frame-by-frame, serving as a robust baseline for data synthesis and simulation in autonomous driving.
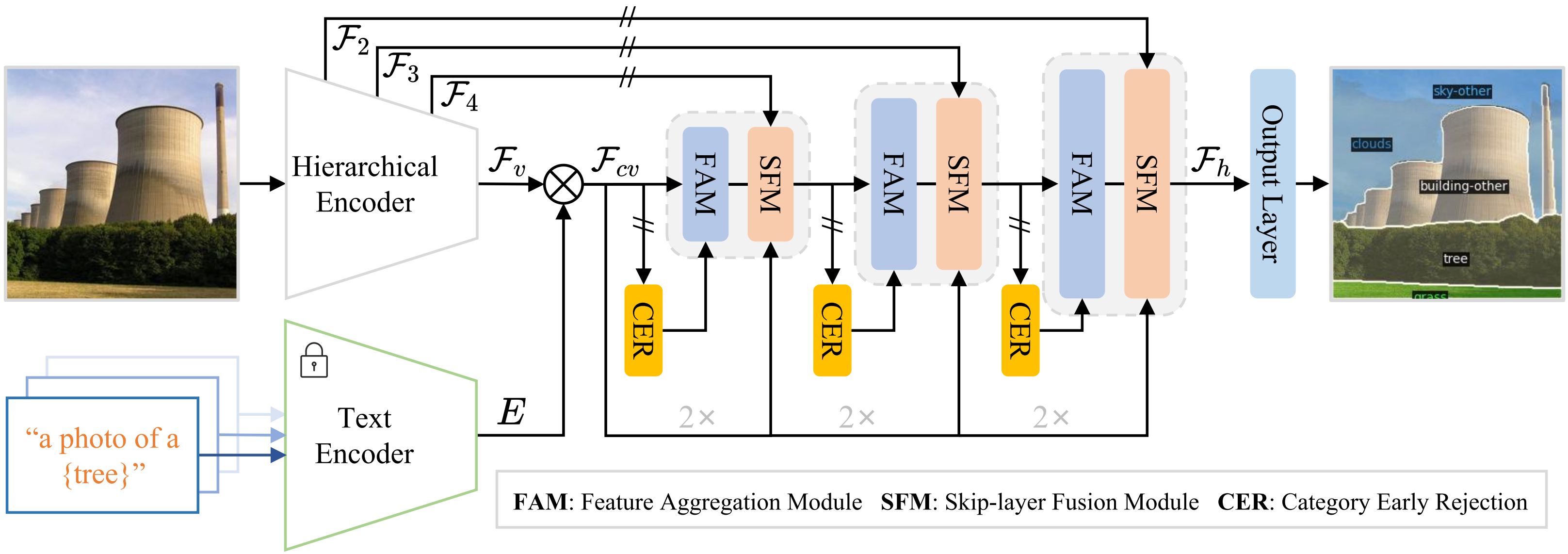
SED: A Simple Encoder-Decoder for Open-Vocabulary Semantic Segmentation
Paper | Code
Bin Xie, Jiale Cao, Jin Xie, Fahad Shahbaz Khan, Yanwei Pang
- By utilizing the simple yet efficient CER module, SED achieves a better trade-off between accuracy and performance for open-vocabulary semantic segmentation.
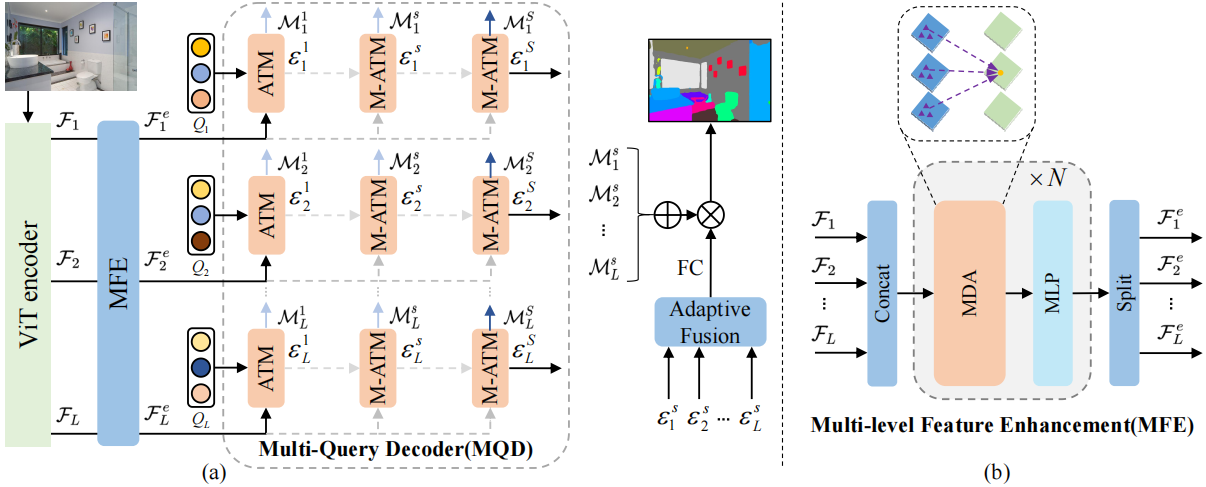
Multi-Query and Multi-Level Enhanced Network for Semantic Segmentation
Paper | Code
Bin Xie, Jiale Cao, Rao Muhammad Anwer, Jin Xie, Jing Nie, Aiping Yang, Yanwei Pang
- To address the limitations of current single-query designs, which fail to fully exploit the diverse, multi-level information available in plain Vision Transformers (ViT), we propose a multi-query and multi-level enhanced network for semantic segmentation.
Service
Invited Reviewer for conferences:
- ICLR 2026, CVPR 2026
- ICLR 2025
Invited Reviewer for journals:
- Pattern Recognition (PR)